- 《对弈程序基本技术》专题
-
- Alpha-Beta搜索
-
- David Eppstein */文
- * 加州爱尔文大学(UC Irvine)信息与计算机科学系
-
- 浅的裁剪
-
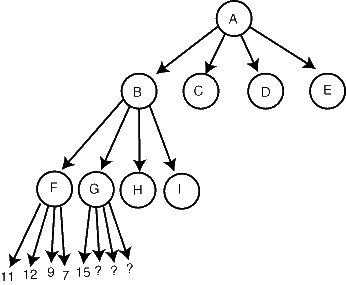
- 假设你用最小-最大搜索(前面讲到的)来搜索下面的树:
-
-
- 你搜索到F,发现子结点的评价分别是11、12、7和9,在这层是棋手甲走,我们希望他选择最好的值,即12。所以,F的最小-最大值是12。
- 现在你开始搜索G,并且第一个子结点就返回15。一旦如此,你就知道G的值至少是15,可能更高(如果另一个子结点比G更好)。这就意味着我们不指望棋手乙走G这步了,因为就棋手乙看来,F的评价12要比G的15(或更高)好,因此我们知道G不在主要变例上。我们可以裁剪(Prune)结点G下面的其他子结点,而不要对它们作出评价,并且立即从G返回,因为对G作更好的评价只是浪费时间。
- 一般来说,像G一样只要有一个子结点返回比G的兄弟结点更好的值(对于结点G要走棋的一方而言),就可以进行裁剪。
-
- 深的裁剪
-
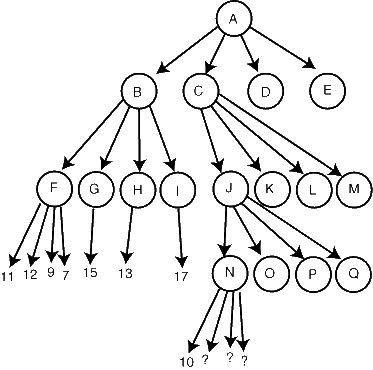
- 我们来讨论更复杂的可能裁剪的情况。例如在同一棵搜索树中,我们评价的G、H和I都比12好,因此12就是结点B的评价。现在我们来搜索结点C,在下面两层我们找到了评价为10的结点N:
-
-
- 我们能用更为复杂的路线来作裁剪。我们知道N会返回10或更小(轮到棋手乙走棋,需要挑最小的)。我们不知道J能否返回10或更小,也不知道J的哪个子结点会更好。如果从J返回到C的是10或者更小的值,那么我们可以在结点C上作裁剪,因为它有更好的兄弟结点B。因此在这种情况下,继续找N的子结点就毫无意义。考虑其他情况,J的其他子结点返回比10更好的值,此时搜索N也是毫无意义的。所以我们只要看到10,就可以放心地从N返回。
-
- Alpha-Beta的伪代码
-
- 一般来说,如果返回值比偶数层的兄弟结点好,我们就可以立即返回。如果我们在搜索过程中,把这些兄弟结点的最小值Beta作为参数来传递,我们就可以进行非常有效的裁剪。我们还用另一个参数Alpha来保存奇数层的结点。用这两个参数来进行裁剪是非常有效的,代码就写在下边。像上次一样,我们用负值最大(Negamax)的形式,即搜索树的层数改变时取负值。
-
- double alphabeta(int depth, double alpha, double beta) {
- if (depth <= 0 || 棋局结束) {
- return evaluation();
- }
- 就当前局面,生成并排序一系列着法;
- for (每个着法 m) {
- 执行着法 m;
- double val = -alphabeta(depth - 1, -beta, -alpha);
- 撤消着法 m;
- if (val >= beta) {
- return val;
- }
- if (val > alpha) {
- alpha = val;
- }
- }
- return alpha;
- }
-
- 下次我们会解释为什么排序这一步是很重要的。
-
- 期望搜索
-
- 在根结点上我们如何为Alpha和Beta设定初值?
- Alpha和Beta定义了一个评价的实数区间(Alpha, Beta),这个区间是我们“感兴趣的”。如果某值比Beta大我们就会做裁剪并立即返回,因为我们知道它不是主要变例的一部分,我们对它的准确值不感兴趣,只需要知道它比Beta大。如果某值比Alpha小,我们不作裁剪,但是仍然对它不感兴趣,因为我们知道搜索树里肯定有一个着法会更好。
- 但是在搜索树的根结点,我们不知道感兴趣的评价是在哪个范围内,如果我们要保证不会因为意外而裁剪掉重要的部分,我们就设Alpha = -Infinity,Beta = Infinity(无穷大)。
- 但是,如果我们使用迭代加深,就可能有办法知道主要变例是怎么样的。假设我们猜其值为x(例如x就是前一次搜索到D -1深度时的值),并设Epsilon为一个很小的值,它代表从D -1深度到D深度搜索评价的期望变化范围。我们可以尝试调用alphabeta(D, x -
Epsilon, x + Epsilon),那么可能发生三种情况:
- (1) 搜索的返回值会落在区间(x -
Epsilon, x + Epsilon)内。这种情况下,我们知道它返回的是正确值,我们就能放心地选择这个着法,在搜索树中这个着法指向具有返回值的那个结点。
- (2) 搜索会返回一个值v > x + Epsilon。这种情况下,我们知道搜索结果也至少是 x + Epsilon,但是我们不知道它到底是几(正确的主要变例可能被裁剪掉了,因为我们看到有别的着法的值大于Beta)。我们必须把我们所猜的值x调整得更高,然后再试一次(可能还要用更大的Epsilon)。这种情况称为“高出边界”(Fail High)。
- (3) 搜索会返回一个值v < x -
Epsilon。这种情况下,我们知道搜索结果也最多是 x + Epsilon,但是我们不知道它到底是几。我们必须把我们所猜的值x调整得更低,然后再试一次(可能还要用更大的Epsilon)。这种情况称为“低出边界”(Fail Low)。
- 即便有两种可能失败的情况,使用期望搜索(用一个比(-Infinity, Infinity)更小的区间(Alpha, Beta))总体来说效率会有所提高,因为它作了更多的裁剪。
-
- 分析
-
- 让我们对Alpha-Beta搜索作一下分析,来知道它为什么是个很有用的算法。跟普通的算法不同,我们采用“Beta情况的分析”,即假设任何可能的情况下都会发生Alpha-Beta裁剪。下一次我们会知道如何让Alpha-Beta搜索接近我们的所分析的情况。在这里我只考虑浅的裁剪,因为它会让分析变得更加简单。
- 在最好的情况下,除了主要变例上的结点不会裁剪外(如果这个结点也被裁剪了,那么整个算法会高出边界或低出边界,这当然不是最好的情况),在裁剪前,深D -1层的每个结点只会搜索一个深D层的子结点。
- 但是在深D -2层时,谁也没有被裁剪,因为所有的子结点都返回大于或等于Beta的值,而D -2层是要取负数,因此它们都小于或等于Alpha。
- 继续朝树根走,D
-3层的每个结点(除了主要变例外)都被裁剪,而D -4层谁也没被裁剪,等等。
- 因此,如果搜索树的分枝因子是B,那么在搜索树一半的深度上,结点以因子B作增长,而在另一半的深度上则保持不变(我们忽略了主要变例)。所以这个搜索树所有要搜索的结点数,粗略地写成BD/2 = sqrt(B)D。因此Alpha-Beta搜索最终可以将分枝因子减少为原来的平方根那么多,因此它可以让我们搜索原来两倍的深度。正因为这个原因,它是所有基于最小-最大策略的棋类对弈程序的最重要的算法。
- 【译注:原作者一开始提到的“浅的裁剪”和“深的裁剪”这两个概念,实际上包含了Alpha-Beta搜索的两个层次,前者只是用过传递参数Beta对搜索树作了部分裁剪,可以称为Beta搜索,而后者增加一个传递参数Alpha,使得裁剪更加充分,这就形成了Alpha-Beta搜索。
- Beta搜索的伪代码是:
-
- double alphabeta(int depth, double
beta) {
- if (depth <= 0 ||
棋局结束) {
- return evaluation();
- }
- 就当前局面,生成并排序一系列着法;
- double alpha = -infty;
- for (每个着法 m) {
- 执行着法 m;
- double val = -alphabeta(depth
- 1, -alpha);
- 撤消着法 m;
- if (val >= beta) {
- return val;
- }
- if (val > alpha) {
- alpha = val;
- }
- }
- return alpha;
- }
-
- 对红色部分加一些改进,就变成Alpha-Beta搜索的伪代码了。】
-
- 原文:http://www.ics.uci.edu/~eppstein/180a/970422.html
- 译者:象棋百科全书网 (webmaster@xqbase.com)
- 类型:全译加译注
上一篇 基本搜索方法——简介(一)
下一篇 基本搜索方法——简介(三)
返 回 象棋百科全书——电脑象棋